
CSDN博客转高清PDF
本文于2519天之前发表,文中内容可能已经过时。
起源:主要是为了学习ffmpeg,然后看到雷神大人的博客太好了(但是CSDN广告太多了….),就爬取下来了,理论上可以爬取所有的csdn
突然想起可能还有小伙伴要用这个,资料下载见文末
效果:
先看疗效—–雷神高清无码博客图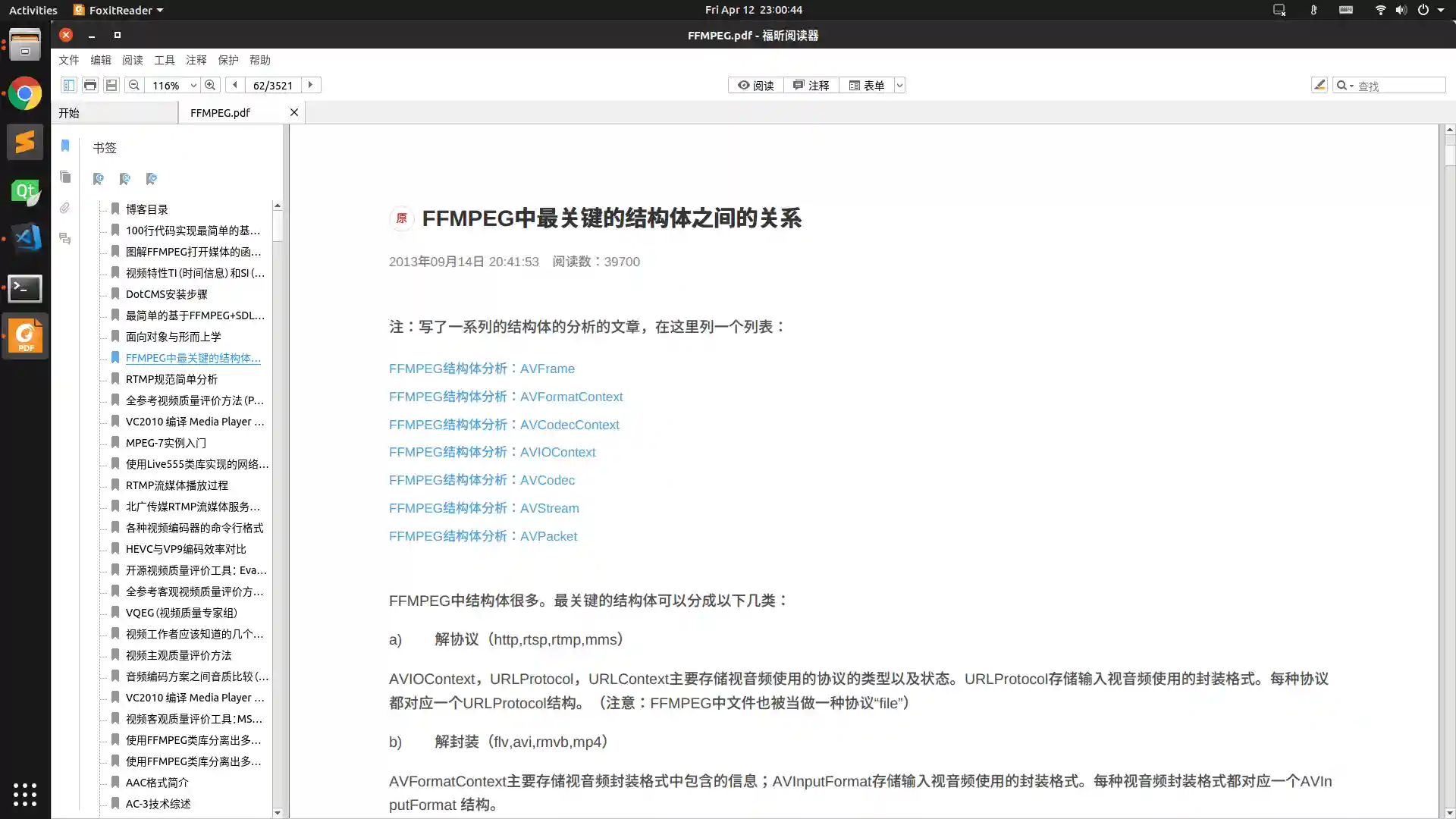
用法:
1 | $ python csdn.py |
所需库:(标注库除外)
- pdfkit
- PyPDF2
- bs4
致敬雷神大人!!!!
实现步骤:
获取目标用户名:
找到目标博客地址,得到用户名如: https://blog.csdn.net/leixiaohua1020 的用户名为leixiaohua1020获取文章列表:
网址格式为: https://blog.csdn.net/用户名/article/list/页码?
从1依次增加上述网址中的页码,当出现”空空如也”的时候即超过了最后一页,可作为终止条件(代码中的getPageByIndex函数)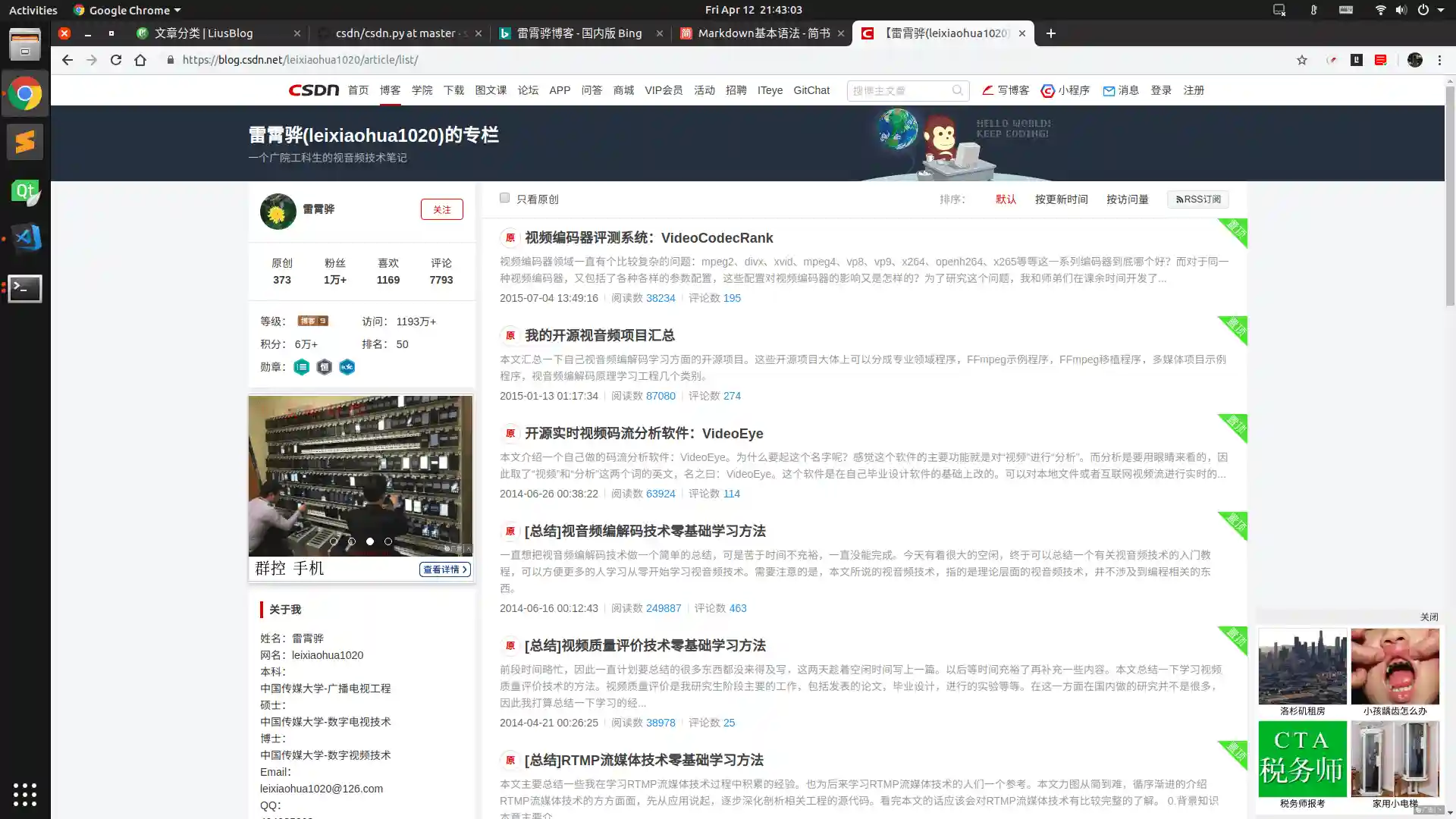
获取文章链接:
在上一步中得到的目录页面中通过chrome调试模式可以发现所有文章都在class=”article-list”的div中,而且链接在子div的class=”article-item-box”中的href中(代码中的getArticlesInPage函数)
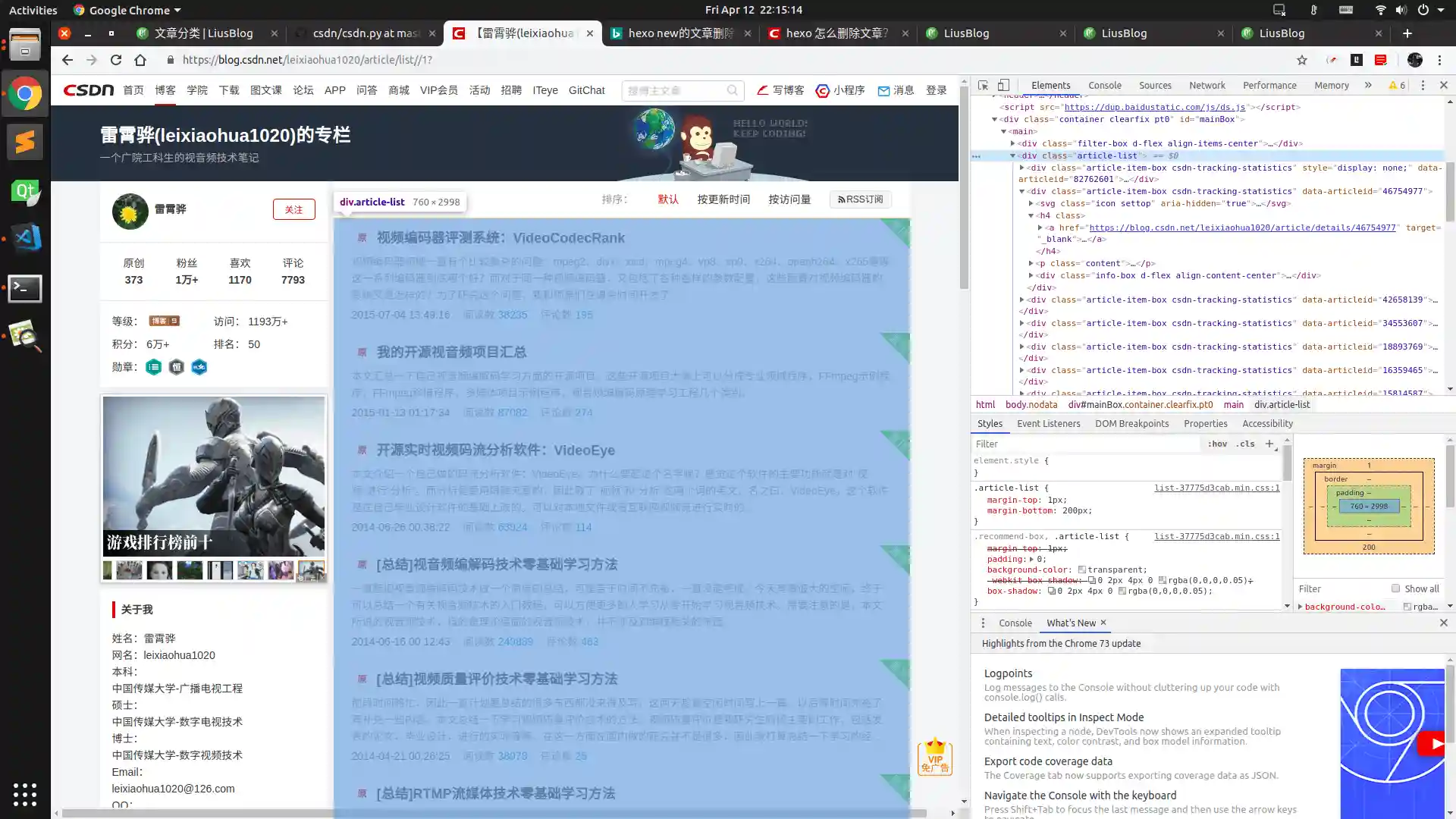
获取文章内容:
这一步没啥好说的,拿到网址后直接开干(getArticleByUrl函数)数据清洗并生成PDF:
本步骤的目的主要是进行去广告,同时尽可能的保留博客的原汁原味主要在函数startThreadPool中完成
①cleanHtmlData主要对数据进行清洗,需要一点html知识
②为了加快生成速度,开辟了线程池主要调用函数doConvert
③生成pdf主要用到了pdfkit中的from_string()函数
PDF合并:
①生成目录
②添加书签(带跳转链接)
数据库:
为了减少服务器压力使用了数据库(同时也方便我们自己,只需要爬取一次)
代码:
代码在我的github中就有了https://github.com/spygg/csdn/
ps:
因为CSDN可能会进行反爬所以请随时关注本人github
pps:
请低调使用!
后记:
话说这个项目也折腾了我好几天,刚开始把所有的html弄到一个页面中想使用chrome导出为PDF功能,谁知道在本人的8g内存i7处理器的电脑上连续跑了几天后电脑直接卡死,试了几次均无效后痛定思痛才想起了化整为零,后面为了加快转化进度开辟了几十个线程来搞也是不错的
资料下载
由于仓库限制大小100M只能分卷压缩,按照下面文件名重命名然后合并解压
leixiaohua1020.7z.001
leixiaohua1020.7z.002
leixiaohua1020.7z.003
leixiaohua1020.7z.004
leixiaohua1020.7z.005
leixiaohua1020.7z.006
leixiaohua1020.7z.007
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的支持是我前行的动力!